I am using web scraping on several sites to get information like prices from e-commerce sites and meter readings, balance amount etc from my apartment service provider portal. This is fairly simple to do in python using “requests” and “beautifulsoup” modules.
Recently, my apartment service provider revamped their website in ASP.NET. I thought it was just another site and login, parsing should be straight forward. But passing user, password and other form inputs didn’t worked.
Upon closely looking at source of login page and page after login, I found “input” fields were different like “ctl00$MainContent$txtSiteID” and there were many random hidden “input” fields like “__VIEWSTATE”, “__VIEWSTATEGENERATOR”, “__EVENTVALIDATION”.
To handle these hidden inputs, you have to first get their values and then pass them in form submit request. Here is the code which does login and fetches data values of interest and then pumps them into influxdb.
#!/usr/bin/python3
import requests
from requests.auth import HTTPBasicAuth
from bs4 import BeautifulSoup
dburi = 'http://localhost:8086/write?db=pesdb'
dbuser = 'pesuser'
dbpass = 'pespass'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT x.y; Win64; x64; rv:10.0) Gecko/20100101 Firefox/10.0'
}
LoginData = {
'ctl00$MainContent$txtSiteID': 'xxxxx',
'ctl00$MainContent$txtCustomerID': 'xxxxx',
'ctl00$MainContent$txtPassword': 'xxxxxxx',
'ctl00$MainContent$Button1': 'Login'
}
with requests.Session() as s:
url = "http://pesonline.co.in:8080/pesenduser/LoginPage.aspx"
r = s.get(url, headers=headers)
soup = BeautifulSoup(r.content, 'html.parser')
LoginData['__VIEWSTATE'] = soup.find('input', attrs={'id': '__VIEWSTATE'})['value']
LoginData['__VIEWSTATEGENERATOR'] = soup.find('input', attrs={'id': '__VIEWSTATEGENERATOR'})['value']
LoginData['__EVENTVALIDATION'] = soup.find('input', attrs={'id': '__EVENTVALIDATION'})['value']
r = s.post(url, data=LoginData, headers=headers)
soup = BeautifulSoup(r.content, 'html.parser')
MeterID = soup.find("span", id="MainContent_lblMeterID").contents[0]
KwhMains = soup.find("span", id="MainContent_lblKwhMains").contents[0]
KwhDG = soup.find("span", id="MainContent_lblKwhDG").contents[0]
LiveBalance = soup.find("span", id="MainContent_lblLiveBalance").contents[0]
CamLiveBalance = soup.find("span", id="MainContent_lblCamLiveBalance").contents[0]
KwActual = soup.find("span", id="MainContent_lblKwActual").contents[0]
DgWorking = soup.find("span", id="MainContent_lblDgWorking").contents[0]
if DgWorking == "Mains":
DgWorking = 0
else:
DgWorking = 1
dbpayload = "pesdata,city={},sector={},complex={},block={},unit={},MeterID={} KwhMains={},KwhDG={},LiveBalance={},CamLiveBalance={},KwActual={},DgWorking={}".format('Gurgaon', '85', 'Carnation', 'D5', '902', MeterID, KwhMains, KwhDG, LiveBalance, CamLiveBalance, KwActual, DgWorking)
print(dbpayload)
dbres=requests.post(dburi, data=dbpayload, auth=HTTPBasicAuth(dbuser, dbpass))
print(dbres.status_code)Above code is executed every one hour from cron and collects timeseries data in influxdb.
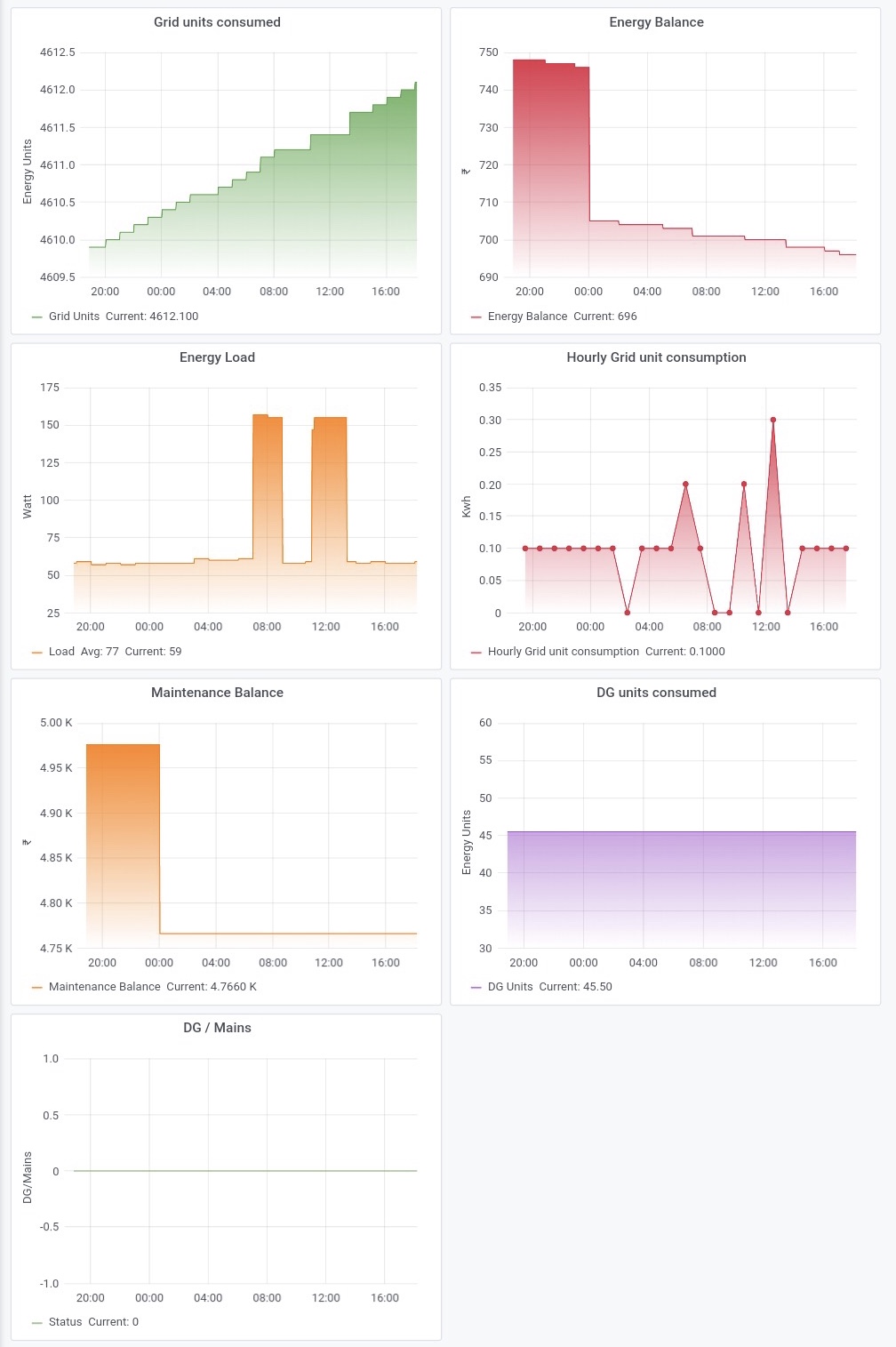
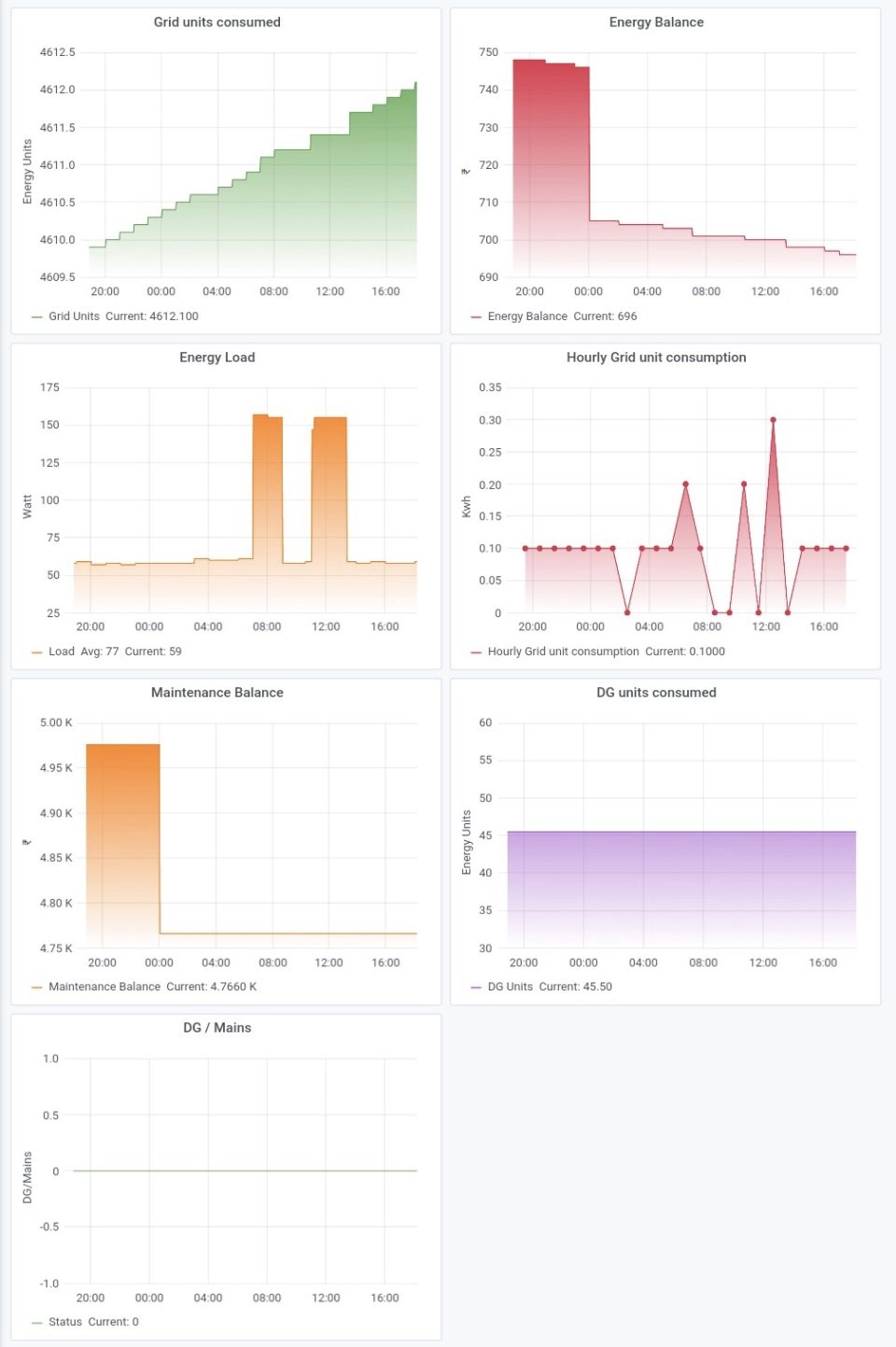
I have also prepared a few visualisations on top of influxdb data in grafana. Here is how these look like.
Related Posts